Who Supervises The Supervisors?
From Bad to Good

Supervisors are one of the most useful part of OTP you'll get to use. We've seen basic supervisors back in Errors and Processes and in Designing a Concurrent Application. We've seen them as a way to keep our software going in case of errors by just restarting the faulty processes.
To be more detailed, our supervisors would start a worker process, link to it, and trap exit signals with process_flag(trap_exit,true) to know when the process died and restart it. This is fine when we want restarts, but it's also pretty dumb. Let's imagine that you're using the remote control to turn the TV on. If it doesn't work the first time, you might try once or twice just in case you didn't press right or the signal went wrong. Our supervisor, if it was trying to turn that very TV on, would keep trying forever, even if it turned out that the remote had no batteries or didn't even fit the TV. A pretty dumb supervisor.
Something else that was dumb about our supervisors is that they could only watch one worker at a time. Don't get me wrong, it's sometimes useful to have one supervisor for a single worker, but in large applications, this would mean you could only have a chain of supervisors, not a tree. How would you supervise a task where you need 2 or 3 workers at once? With our implementation, it just couldn't be done.
The OTP supervisors, fortunately, provide the flexibility to handle such cases (and more). They let you define how many times a worker should be restarted in a given period of time before giving up. They let you have more than one worker per supervisor and even let you pick between a few patterns to determine how they should depend on each other in case of a failure.
Supervisor Concepts
Supervisors are one of the simplest behaviours to use and understand, but one of the hardest behaviours to write a good design with. There are various strategies related to supervisors and application design, but before going there we need to understand more basic concepts because otherwise it's going to be pretty hard.
One of the words I have used in the text so far without much of a definition is the word 'worker'. Workers are defined a bit in opposition of supervisors. If supervisors are supposed to be processes which do nothing but make sure their children are restarted when they die, workers are processes in charge of doing actual work, and that may die while doing so. They are usually not trusted.
Supervisors can supervise workers and other supervisors, while workers should never be used in any position except under another supervisor:
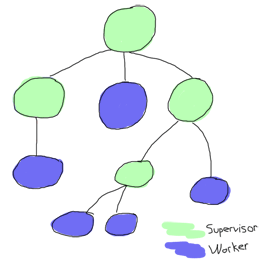
Why should every process be supervised? Well the idea is simple: if for some reason you're spawning unsupervised processes, how can you be sure they are gone or not? If you can't measure something, it doesn't exist. Now if a process exists in the void away from all your supervision trees, how do you know it exists or not? How did it get there? Will it happen again?
If it does happen, you'll find yourself leaking memory very slowly. So slowly your VM might suddenly die because it no longer has memory, and so slowly you might not be able to easily track it until it happens again and again. Of course, you might say "If I take care and know what I'm doing, things will be fine". Maybe they will be fine, yeah. Maybe they won't. In a production system, you don't want to be taking chances, and in the case of Erlang, it's why you have garbage collection to begin with. Keeping things supervised is pretty useful.
Another reason why it's useful is that it allows to terminate applications in good order. It will happen that you'll write Erlang software that is not meant to run forever. You'll still want it to terminate cleanly though. How do you know everything is ready to be shut down? With supervisors, it's easy. Whenever you want to terminate an application, you have the top supervisor of the VM shut down (this is done for you with functions like init:stop/1). Then that supervisor asks each of its children to terminate. If some of the children are supervisors, they do the same:

This gives you a well-ordered VM shutdown, something that is very hard to do without having all of your processes being part of the tree.
Of course, there are times where your process will be stuck for some reason and won't terminate correctly. When that happens, supervisors have a way to brutally kill the process.
This is it for the basic theory of supervisors. We have workers, supervisors, supervision trees, different ways to specify dependencies, ways to tell supervisors when to give up on trying or waiting for their children, etc. This is not all that supervisors can do, but for now, this will let us cover the basic content required to actually use them.
Using Supervisors
This has been a very violent chapter so far: parents spend their time binding their children to trees, forcing them to work before brutally killing them. We wouldn't be real sadists without actually implementing it all though.
When I said supervisors were simple to use, I wasn't kidding. There is a single callback function to provide: init/1. It takes some arguments and that's about it. The catch is that it returns quite a complex thing. Here's an example return from a supervisor:
{ok, {{one_for_all, 5, 60},
[{fake_id,
{fake_mod, start_link, [SomeArg]},
permanent,
5000,
worker,
[fake_mod]},
{other_id,
{event_manager_mod, start_link, []},
transient,
infinity,
worker,
dynamic}]}}.
Say what? Yeah, that's pretty complex. A general definition might be a bit simpler to work with:
{ok, {{RestartStrategy, MaxRestart, MaxTime},[ChildSpecs]}}.
Where ChildSpec stands for a child specification. RestartStrategy can be any of one_for_one, rest_for_one, one_for_all and simple_one_for_one.
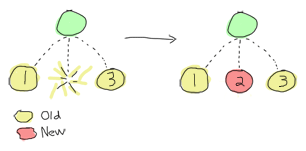
one_for_one
One for one is an intuitive restart strategy. It basically means that if your supervisor supervises many workers and one of them fails, only that one should be restarted. You should use one_for_one whenever the processes being supervised are independent and not really related to each other, or when the process can restart and lose its state without impacting its siblings.
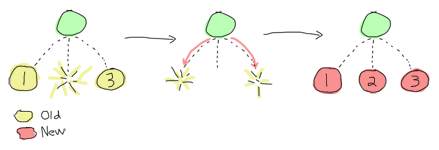
one_for_all
One for all has little to do with musketeers. It's to be used whenever all your processes under a single supervisor heavily depend on each other to be able to work normally. Let's say you have decided to add a supervisor on top of the trading system we implemented back in the Rage Against The Finite State Machines chapter. It wouldn't actually make sense to restart only one of the two traders if one of them crashed because their state would be out of sync. Restarting both of them at once would be a saner choice and one_for_all would be the strategy for that.
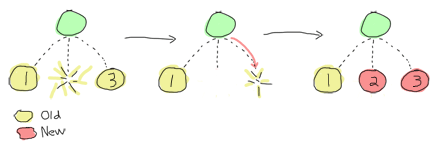
rest_for_one
This is a more specific kind of strategy. Whenever you have to start processes that depend on each other in a chain (A starts B, which starts C, which starts D, etc.), you can use rest_for_one. It's also useful in the case of services where you have similar dependencies (X works alone, but Y depends on X and Z depends on both). What a rest_for_one restarting strategy does, basically, is make it so if a process dies, all the ones that were started after it (depend on it) get restarted, but not the other way around.
simple_one_for_one
The simple_one_for_one restart strategy isn't the most simple one. We'll see it in more details when we get to use it, but it basically makes it so it takes only one kind of children, and it's to be used when you want to dynamically add them to the supervisor, rather than having them started statically.
To say it a bit differently, a simple_one_for_one supervisor just sits around there, and it knows it can produce one kind of child only. Whenever you want a new one, you ask for it and you get it. This kind of thing could theoretically be done with the standard one_for_one supervisor, but there are practical advantages to using the simple version.
Note: one of the big differences between one_for_one and simple_one_for_one is that one_for_one holds a list of all the children it has (and had, if you don't clear it), started in order, while simple_one_for_one holds a single definition for all its children and works using a dict to hold its data. Basically, when a process crashes, the simple_one_for_one supervisor will be much faster when you have a large number of children.
Restart limits
The last part of the RestartStrategy tuple is the couple of variables MaxRestart and MaxTime. The idea is basically that if more than MaxRestarts happen within MaxTime (in seconds), the supervisor just gives up on your code, shuts it down then kills itself to never return (that's how bad it is). Fortunately, that supervisor's supervisor might still have hope in its children and start them all over again.
Child Specifications
And now for the ChildSpec part of the return value. ChildSpec stands for Child Specification. Earlier we had the following two ChildSpecs:
[{fake_id,
{fake_mod, start_link, [SomeArg]},
permanent,
5000,
worker,
[fake_mod]},
{other_id,
{event_manager_mod, start_link, []},
transient,
infinity,
worker,
dynamic}]
The child specification can be described in a more abstract form as:
{ChildId, StartFunc, Restart, Shutdown, Type, Modules}.
ChildId
The ChildId is just an internal name used by the supervisor internally. You will rarely need to use it yourself, although it might be useful for debugging purposes and sometimes when you decide to actually get a list of all the children of a supervisor. Any term can be used for the Id.
StartFunc
StartFunc is a tuple that tells how to start the child. It's the standard {M,F,A} format we've used a few times already. Note that it is very important that the starting function here is OTP-compliant and links to its caller when executed (hint: use gen_*:start_link() wrapped in your own module, all the time).
Restart
Restart tells the supervisor how to react when that particular child dies. This can take three values:
- permanent
- temporary
- transient
A permanent process should always be restarted, no matter what. The supervisors we implemented in our previous applications used this strategy only. This is usually used by vital, long-living processes (or services) running on your node.
On the other hand, a temporary process is a process that should never be restarted. They are for short-lived workers that are expected to fail and which have few bits of code who depend on them.
Transient processes are a bit of an in-between. They're meant to run until they terminate normally and then they won't be restarted. However, if they die of abnormal causes (exit reason is anything but normal), they're going to be restarted. This restart option is often used for workers that need to succeed at their task, but won't be used after they do so.
You can have children of all three kinds mixed under a single supervisor. This might affect the restart strategy: a one_for_all restart won't be triggered by a temporary process dying, but that temporary process might be restarted under the same supervisor if a permanent process dies first!
Shutdown
Earlier in the text, I mentioned being able to shut down entire applications with the help of supervisors. This is how it's done. When the top-level supervisor is asked to terminate, it calls exit(ChildPid, shutdown) on each of the Pids. If the child is a worker and trapping exits, it'll call its own terminate function. Otherwise, it's just going to die. When a supervisor gets the shutdown signal, it will forward it to its own children the same way.
The Shutdown value of a child specification is thus used to give a deadline on the termination. On certain workers, you know you might have to do things like properly close files, notify a service that you're leaving, etc. In these cases, you might want to use a certain cutoff time, either in milliseconds or infinity if you are really patient. If the time passes and nothing happens, the process is then brutally killed with exit(Pid, kill). If you don't care about the child and it can pretty much die without any consequences without any timeout needed, the atom brutal_kill is also an acceptable value. brutal_kill will make it so the child is killed with exit(Pid, kill), which is untrappable and instantaneous.
Choosing a good Shutdown value is sometimes complex or tricky. If you have a chain of supervisors with Shutdown values like: 5000 -> 2000 -> 5000 -> 5000, the two last ones will likely end up brutally killed, because the second one had a shorter cutoff time. It is entirely application dependent, and few general tips can be given on the subject.
Note: it is important to note that simple_one_for_one children are not respecting this rule with the Shutdown time. In the case of simple_one_for_one, the supervisor will just exit and it will be left to each of the workers to terminate on their own, after their supervisor is gone.
Type
Type simply lets the supervisor know whether the child is a worker or a supervisor. This will be important when upgrading applications with more advanced OTP features, but you do not really need to care about this at the moment — only tell the truth and everything should be alright. You've got to trust your supervisors!
Modules
Modules is a list of one element, the name of the callback module used by the child behavior. The exception to that is when you have callback modules whose identity you do not know beforehand (such as event handlers in an event manager). In this case, the value of Modules should be dynamic so that the whole OTP system knows who to contact when using more advanced features, such as releases.
update:
Since version 18.0, the supervisor structure can be provided as maps, of the form {#{strategy => RestartStrategy, intensity => MaxRestart, => MaxTime}, [#{id => ChildId, start => StartFunc, restart => Restart, shutdown => Shutdown, type => Type, modules => Module}}.
This is pretty much the same structure as the existing one, but with maps instead of tuples. The supervisor module defines some default values, but to be clear and readable for people who will maintain your code, having the whole specification explicit is a good idea.
Hooray, we now have the basic knowledge required to start supervised processes. You can take a break and digest it all, or move forward with more content!

Testing it Out
Some practice is in order. And in term of practice, the perfect example is a band practice. Well not that perfect, but bear with me for a while, because we'll go on quite an analogy as a pretext to try our hand at writing supervisors and whatnot.
We're managing a band named *RSYNC, made of programmers playing a few common instruments: a drummer, a singer, a bass player and a keytar player, in memory of all the forgotten 80's glory. Despite a few retro hit song covers such as 'Thread Safety Dance' and 'Saturday Night Coder', the band has a hard time getting a venue. Annoyed with the whole situation, I storm into your office with yet another sugar rush-induced idea of simulating a band in Erlang because "at least we won't be hearing our guys". You're tired because you live in the same apartment as the drummer (who is the weakest link in this band, but they stick together with him because they do not know any other drummer, to be honest), so you accept.
Musicians
The first thing we can do is write the individual band members. For our use case, the musicians module will implement a gen_server. Each musician will take an instrument and a skill level as a parameter (so we can say the drummer sucks, while the others are alright). Once a musician has spawned, it shall start playing. We'll also have an option to stop them, if needed. This gives us the following module and interface:
-module(musicians).
-behaviour(gen_server).
-export([start_link/2, stop/1]).
-export([init/1, handle_call/3, handle_cast/2,
handle_info/2, code_change/3, terminate/2]).
-record(state, {name="", role, skill=good}).
-define(DELAY, 750).
start_link(Role, Skill) ->
gen_server:start_link({local, Role}, ?MODULE, [Role, Skill], []).
stop(Role) -> gen_server:call(Role, stop).
I've defined a ?DELAY macro that we'll use as the standard time span between each time a musician will show himself as playing. As the record definition shows, we'll also have to give each of them a name:
init([Role, Skill]) ->
%% To know when the parent shuts down
process_flag(trap_exit, true),
%% sets a seed for random number generation for the life of the process
%% uses the current time to do it. Unique value guaranteed by now()
random:seed(now()),
TimeToPlay = random:uniform(3000),
Name = pick_name(),
StrRole = atom_to_list(Role),
io:format("Musician ~s, playing the ~s entered the room~n",
[Name, StrRole]),
{ok, #state{name=Name, role=StrRole, skill=Skill}, TimeToPlay}.
Two things go on in the init/1 function. First we start trapping exits. If you recall the description of the terminate/2 from the Generic Servers chapter, we need to do this if we want terminate/2 to be called when the server's parent shuts down its children. The rest of the init/1 function is setting a random seed (so that each process gets different random numbers) and then creates a random name for itself. The functions to create the names are:
%% Yes, the names are based off the magic school bus characters'
%% 10 names!
pick_name() ->
%% the seed must be set for the random functions. Use within the
%% process that started with init/1
lists:nth(random:uniform(10), firstnames())
++ " " ++
lists:nth(random:uniform(10), lastnames()).
firstnames() ->
["Valerie", "Arnold", "Carlos", "Dorothy", "Keesha",
"Phoebe", "Ralphie", "Tim", "Wanda", "Janet"].
lastnames() ->
["Frizzle", "Perlstein", "Ramon", "Ann", "Franklin",
"Terese", "Tennelli", "Jamal", "Li", "Perlstein"].
Alright! We can move on to the implementation. This one is going to be pretty trivial for handle_call and handle_cast:
handle_call(stop, _From, S=#state{}) ->
{stop, normal, ok, S};
handle_call(_Message, _From, S) ->
{noreply, S, ?DELAY}.
handle_cast(_Message, S) ->
{noreply, S, ?DELAY}.
The only call we have is to stop the musician server, which we agree to do pretty quick. If we receive an unexpected message, we do not reply to it and the caller will crash. Not our problem. We set the timeout in the {noreply, S, ?DELAY} tuples, for one simple reason that we'll see right now:
handle_info(timeout, S = #state{name=N, skill=good}) ->
io:format("~s produced sound!~n",[N]),
{noreply, S, ?DELAY};
handle_info(timeout, S = #state{name=N, skill=bad}) ->
case random:uniform(5) of
1 ->
io:format("~s played a false note. Uh oh~n",[N]),
{stop, bad_note, S};
_ ->
io:format("~s produced sound!~n",[N]),
{noreply, S, ?DELAY}
end;
handle_info(_Message, S) ->
{noreply, S, ?DELAY}.
Each time the server times out, our musicians are going to play a note. If they're good, everything's going to be completely fine. If they're bad, they'll have one chance out of 5 to miss and play a bad note, which will make them crash. Again, we set the ?DELAY timeout at the end of each non-terminating call.
Then we add an empty code_change/3 callback, as required by the 'gen_server' behaviour:
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
And we can set the terminate function:
terminate(normal, S) ->
io:format("~s left the room (~s)~n",[S#state.name, S#state.role]);
terminate(bad_note, S) ->
io:format("~s sucks! kicked that member out of the band! (~s)~n",
[S#state.name, S#state.role]);
terminate(shutdown, S) ->
io:format("The manager is mad and fired the whole band! "
"~s just got back to playing in the subway~n",
[S#state.name]);
terminate(_Reason, S) ->
io:format("~s has been kicked out (~s)~n", [S#state.name, S#state.role]).

We've got many different messages here. If we terminate with a normal reason, it means we've called the stop/1 function and so we display the the musician left of his/her own free will. In the case of a bad_note message, the musician will crash and we'll say that it's because the manager (the supervisor we'll soon add) kicked him out of the game.
Then we have the shutdown message, which will come from the supervisor. Whenever that happens, it means the supervisor decided to kill all of its children, or in our case, fired all of his musicians. We then add a generic error message for the rest.
Here's a simple use case of a musician:
1> c(musicians).
{ok,musicians}
2> musicians:start_link(bass, bad).
Musician Ralphie Franklin, playing the bass entered the room
{ok,<0.615.0>}
Ralphie Franklin produced sound!
Ralphie Franklin produced sound!
Ralphie Franklin played a false note. Uh oh
Ralphie Franklin sucks! kicked that member out of the band! (bass)
3>
=ERROR REPORT==== 6-Mar-2011::03:22:14 ===
** Generic server bass terminating
** Last message in was timeout
** When Server state == {state,"Ralphie Franklin","bass",bad}
** Reason for termination ==
** bad_note
** exception error: bad_note
So we have Ralphie playing and crashing after a bad note. Hooray. If you try the same with a good musician, you'll need to call our musicians:stop(Instrument) function in order to stop all the playing.
Band Supervisor
We can now work with the supervisor. We'll have three grades of supervisors: a lenient one, an angry one, and a total jerk. The difference between them is that the lenient supervisor, while still a very pissy person, will fire a single member of the band at a time (one_for_one), the one who fails, until he gets fed up, fires them all and gives up on bands. The angry supervisor, on the other hand, will fire some of them (rest_for_one) on each mistake and will wait shorter before firing them all and giving up. Then the jerk supervisor will fire the whole band each time someone makes a mistake, and give up if the bands fail even less often.
-module(band_supervisor).
-behaviour(supervisor).
-export([start_link/1]).
-export([init/1]).
start_link(Type) ->
supervisor:start_link({local,?MODULE}, ?MODULE, Type).
%% The band supervisor will allow its band members to make a few
%% mistakes before shutting down all operations, based on what
%% mood he's in. A lenient supervisor will tolerate more mistakes
%% than an angry supervisor, who'll tolerate more than a
%% complete jerk supervisor
init(lenient) ->
init({one_for_one, 3, 60});
init(angry) ->
init({rest_for_one, 2, 60});
init(jerk) ->
init({one_for_all, 1, 60});
The init definition doesn't finish there, but this lets us set the tone for each of the kinds of supervisor we want. The lenient one will only restart one musician and will fail on the fourth failure in 60 seconds. The second one will accept only 2 failures and the jerk supervisor will have very strict standards there!
Now let's finish the function and actually implement the band starting functions and whatnot:
init({RestartStrategy, MaxRestart, MaxTime}) ->
{ok, {{RestartStrategy, MaxRestart, MaxTime},
[{singer,
{musicians, start_link, [singer, good]},
permanent, 1000, worker, [musicians]},
{bass,
{musicians, start_link, [bass, good]},
temporary, 1000, worker, [musicians]},
{drum,
{musicians, start_link, [drum, bad]},
transient, 1000, worker, [musicians]},
{keytar,
{musicians, start_link, [keytar, good]},
transient, 1000, worker, [musicians]}
]}}.
So we can see we'll have 3 good musicians: the singer, bass player and keytar player. The drummer is terrible (which makes you pretty mad). The musicians have different Restarts (permanent, transient or temporary), so the band could never work without a singer even if the current one left of his own will, but could still play real fine without a bass player, because frankly, who gives a crap about bass players?
That gives us a functional band_supervisor module, which we can now try:
3> c(band_supervisor).
{ok,band_supervisor}
4> band_supervisor:start_link(lenient).
Musician Carlos Terese, playing the singer entered the room
Musician Janet Terese, playing the bass entered the room
Musician Keesha Ramon, playing the drum entered the room
Musician Janet Ramon, playing the keytar entered the room
{ok,<0.623.0>}
Carlos Terese produced sound!
Janet Terese produced sound!
Keesha Ramon produced sound!
Janet Ramon produced sound!
Carlos Terese produced sound!
Keesha Ramon played a false note. Uh oh
Keesha Ramon sucks! kicked that member out of the band! (drum)
... <snip> ...
Musician Arnold Tennelli, playing the drum entered the room
Arnold Tennelli produced sound!
Carlos Terese produced sound!
Janet Terese produced sound!
Janet Ramon produced sound!
Arnold Tennelli played a false note. Uh oh
Arnold Tennelli sucks! kicked that member out of the band! (drum)
... <snip> ...
Musician Carlos Frizzle, playing the drum entered the room
... <snip for a few more firings> ...
Janet Jamal played a false note. Uh oh
Janet Jamal sucks! kicked that member out of the band! (drum)
The manager is mad and fired the whole band! Janet Ramon just got back to playing in the subway
The manager is mad and fired the whole band! Janet Terese just got back to playing in the subway
The manager is mad and fired the whole band! Carlos Terese just got back to playing in the subway
** exception error: shutdown
Magic! We can see that only the drummer is fired, and after a while, everyone gets it too. And off to the subway (tubes for the UK readers) they go!
You can try with other kinds of supervisors and it will end the same. The only difference will be the restart strategy:
5> band_supervisor:start_link(angry). Musician Dorothy Frizzle, playing the singer entered the room Musician Arnold Li, playing the bass entered the room Musician Ralphie Perlstein, playing the drum entered the room Musician Carlos Perlstein, playing the keytar entered the room ... <snip> ... Ralphie Perlstein sucks! kicked that member out of the band! (drum) ... The manager is mad and fired the whole band! Carlos Perlstein just got back to playing in the subway
For the angry one, both the drummer and the keytar players get fired when the drummer makes a mistake. This nothing compared to the jerk's behaviour:
6> band_supervisor:start_link(jerk). Musician Dorothy Franklin, playing the singer entered the room Musician Wanda Tennelli, playing the bass entered the room Musician Tim Perlstein, playing the drum entered the room Musician Dorothy Frizzle, playing the keytar entered the room ... <snip> ... Tim Perlstein played a false note. Uh oh Tim Perlstein sucks! kicked that member out of the band! (drum) The manager is mad and fired the whole band! Dorothy Franklin just got back to playing in the subway The manager is mad and fired the whole band! Wanda Tennelli just got back to playing in the subway The manager is mad and fired the whole band! Dorothy Frizzle just got back to playing in the subway
That's most of it for the restart strategies that are not dynamic.
Dynamic Supervision
So far the kind of supervision we've seen has been static. We specified all the children we'd have right in the source code and let everything run after that. This is how most of your supervisors might end up being set in real world applications; they're usually there for the supervision of architectural components. On the other hand, you have supervisors who act over undetermined workers. They're usually there on a per-demand basis. Think of a web server that would spawn a process per connection it receives. In this case, you would want a dynamic supervisors to look over all the different processes you'll have.
Every time a worker is added to a supervisor using the one_for_one, rest_for_one, or one_for_all strategies, the child specification is added to a list in the supervisor, along with a pid and some other information. The child specification can then be used to restart the child and whatnot. Because things work that way, the following interface exists:
- start_child(SupervisorNameOrPid, ChildSpec)
- This adds a child specification to the list and starts the child with it
- terminate_child(SupervisorNameOrPid, ChildId)
- Terminates or brutal_kills the child. The child specification is left in the supervisor
- restart_child(SupervisorNameOrPid, ChildId)
- Uses the child specification to get things rolling.
- delete_child(SupervisorNameOrPid, ChildId)
- Gets rid of the ChildSpec of the specified child
- check_childspecs([ChildSpec])
- Makes sure a child specification is valid. You can use this to try it before using 'start_child/2'.
- count_children(SupervisorNameOrPid)
- Counts all the children under the supervisor and gives you a little comparative list of who's active, how many specs there are, how many are supervisors and how many are workers.
- which_children(SupervisorNameOrPid)
- gives you a list of all the children under the supervisor.
Let's see how this works with musicians, with the output removed (you need to be quick to outrace the failing drummer!)
1> band_supervisor:start_link(lenient).
{ok,0.709.0>}
2> supervisor:which_children(band_supervisor).
[{keytar,<0.713.0>,worker,[musicians]},
{drum,<0.715.0>,worker,[musicians]},
{bass,<0.711.0>,worker,[musicians]},
{singer,<0.710.0>,worker,[musicians]}]
3> supervisor:terminate_child(band_supervisor, drum).
ok
4> supervisor:terminate_child(band_supervisor, singer).
ok
5> supervisor:restart_child(band_supervisor, singer).
{ok,<0.730.0>}
6> supervisor:count_children(band_supervisor).
[{specs,4},{active,3},{supervisors,0},{workers,4}]
7> supervisor:delete_child(band_supervisor, drum).
ok
8> supervisor:restart_child(band_supervisor, drum).
{error,not_found}
9> supervisor:count_children(band_supervisor).
[{specs,3},{active,3},{supervisors,0},{workers,3}]
And you can see how you could dynamically manage the children. This works well for anything dynamic which you need to manage (I want to start this one, terminate it, etc.) and which are in little number. Because the internal representation is a list, this won't work very well when you need quick access to many children.

In these case, what you want is simple_one_for_one. The problem with simple_one_for_one is that it will not allow you to manually restart a child, delete it or terminate it. This loss in flexibility is fortunately accompanied by a few advantages. All the children are held in a dictionary, which makes looking them up fast. There is also a single child specification for all children under the supervisor. This will save you memory and time in that you will never need to delete a child yourself or store any child specification.
For the most part, writing a simple_one_for_one supervisor is similar to writing any other type of supervisor, except for one thing. The argument list in the {M,F,A} tuple is not the whole thing, but is going to be appended to what you call it with when you do supervisor:start_child(Sup, Args). That's right, supervisor:start_child/2 changes API. So instead of doing supervisor:start_child(Sup, Spec), which would call erlang:apply(M,F,A), we now have supervisor:start_child(Sup, Args), which calls erlang:apply(M,F,A++Args).
Here's how we'd write it for our band_supervisor. Just add the following clause somewhere in it:
init(jamband) ->
{ok, {{simple_one_for_one, 3, 60},
[{jam_musician,
{musicians, start_link, []},
temporary, 1000, worker, [musicians]}
]}};
I've made them all temporary in this case, and the supervisor is quite lenient:
1> supervisor:start_child(band_supervisor, [djembe, good]).
Musician Janet Tennelli, playing the djembe entered the room
{ok,<0.690.0>}
2> supervisor:start_child(band_supervisor, [djembe, good]).
{error,{already_started,<0.690.0>}}
Whoops! this happens because we register the djembe player as djembe as part of the start call to our gen_server. If we didn't name them or used a different name for each, it wouldn't cause a problem. Really, here's one with the name drum instead:
3> supervisor:start_child(band_supervisor, [drum, good]).
Musician Arnold Ramon, playing the drum entered the room
{ok,<0.696.0>}
3> supervisor:start_child(band_supervisor, [guitar, good]).
Musician Wanda Perlstein, playing the guitar entered the room
{ok,<0.698.0>}
4> supervisor:terminate_child(band_supervisor, djembe).
{error,simple_one_for_one}
Right. As I said, no way to control children that way.
5> musicians:stop(drum). Arnold Ramon left the room (drum) ok
And this works better.
As a general (and sometimes wrong) hint, I'd tell you to use standard supervisors dynamically only when you know with certainty that you will have few children to supervise and/or that they won't need to be manipulated with any speed and rather infrequently. For other kinds of dynamic supervision, use simple_one_for_one where possible.
update:
Since version R14B03, it is possible to terminate children with the function supervisor:terminate_child(SupRef, Pid). Simple one for one supervision schemes are now possible to make fully dynamic and have become an all-around interesting choice for when you have many processes running a single type of process.
That's about it for the supervision strategies and child specification. Right now you might be having doubts on 'how the hell am I going to get a working application out of that?' and if that's the case, you'll be happy to get to the next chapter, which actually builds a simple application with a short supervision tree, to see how it could be done in the real world.